【问题描述】
昨天我在整理从洗衣店洗干净的一堆袜子,发现我用的方法非常不高效。我用了一个最简单的方法:拿到一只袜子,然后从头到尾去找另外一只袜子。用这种方法需要重复平均超过 n/2*n/4=n2/8 双袜子。
作为一个计算机科学家,我在想我应该怎么做?我立马就想到了根据尺寸颜色排序来得到一个复杂度为O(NlogN)的方法。
哈希或其他“非原地”的方法在这里不可取,因为我不可能复制袜子(要是可以的话就好了)。
因此,这个基本问题是:
给一堆袜子,总数 n 双,即包含 2n 只袜子(袜子是乱放的,即不是成对放的),假设每只袜子都有一个确定的且能和它配对的袜子,问:如何用最快最有效的算法找出每只袜子与之配对的另一个袜子,并且最多使用对数级别的额外空间?
如果答案能够考虑到下面的几个方面,我会非常高兴:(我希望答案能够考虑到下面的几个方面:)
该算法要同样适用于巨大数量的袜子。
现实中袜子数量不会很多,我和我配偶的袜子加起来不超过30双(我们俩的袜子非常容易区分,这可以被利用吗?)
该问题是否等同于元素唯一性问题(Element distinctness problem)?
【最佳答案】
上面提到的排序虽然可以考虑,但是有点浪费。因为我们不需要有序,我们仅仅需要的是具有“相同”属性的东西;
因此哈希算法就已经足够了,并且还很快。
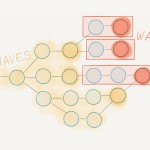
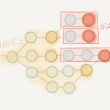
1. 从另一个角度来看堆(一堆袜子)是由袜子的所有颜色形成的。所以遍历输入篮子中的所有袜子并,根据颜色再把他们放到不同的篮子。
2. 遍历上述新形成的每个篮子,再根据其他的一些特性比如形状将袜子放到第二个集合篮子中。
3. 递归地运用上述方法,直到将所有袜子都放到一个非常小的篮子中,最后你可以很容易的来处理。
SQL Server的实现就采用的是这种递归哈希划分方法,当它要进行添加或者合并巨大集合的时候。它将输入划分成了多个集合,而且每个集合都是相互独立的。这个方法对任意数据量和多核CPU都可以得到线性的复杂度。
如果你可以找到一个值,使得每个篮子内的元素数量小到可以很轻松处理的程度,那么你就可以不用递归的划分。不幸的是,我认为袜子没有这样的一个属性。
如果每个袜子都有一个整数形式的”PairID”,这样就可以很容易依据哈希算法PairID%10,将所有袜子放到10个篮子中。
我认为实际上最有效的划分是:用一个长方形的盒子,长方形的一条边代表颜色,另一条边代表形状。(译者注:运用一个二位数组,一维代表颜色,另一维 代表形状)。为什么是一个长方形的盒子?因为这样我们可以只用O(1)的代价,就可以随机访问盒子中的元素。(三维的长方体也可以,但是不合实际)。
【答案更新】
考虑并行处理呢?如果有多个人来共同配对袜子,是否会快点呢?
1.有一个最简单的并行策略,就是多个工人共同处理一篮子的袜子,将袜子配对。这只会加快一点点,假设有100个人处理10堆袜子。多人之间的同步成本(比如说手工碰撞和人类沟通)这样会降低效率和速度(见Universal Scalability Law)。这样会导致死锁吗?不会,因为每一个工人在一个时间只会访问一个篮子。只需要一个锁就可以防止死锁。是否发生活锁(Livelocks)则依赖于工人怎么合作去访问篮子。他们可能使用类似网卡那样的二进制指数退避算法(random backoff ),在物理级别上决定哪些可以独占的访问网线。如果这个方法在网卡上有成效,那也同样适用于那些工人。
2. 如果每个工人都有自己的一个篮子集合那这个规模就会接近无限大了。工人们可以从一个非常大的篮子中拿走袜子,并且在配对所有袜子时候不需要相互交流同步 (因为此时每个人都有自己独有的篮子)。最后再将每个工人所有的篮子合并在一起。我认为如果所有工人能够形成一个聚合树,那么这个问题可以在复杂度 O(logW*P) (W代表工人的数量,P是平均每个工人的堆数量)内完成。
元素唯一性会如何呢?前文也提到了,元素唯一性可以在O(n)内解决。如果你只需要一个分派步骤(我之前推荐分发多次,是因为人计算能力不强的原 因。如果你使用md5来进行分发,一次就足够了。因为md5可以把颜色、长度、图案都考虑进去,是一个包含所有属性的完美哈希),袜子问题同样也可以在 O(n)内处理完。
很明显,所有算法最快也不可能超过O(n),所以我们达到了最优下界。
尽管输出可能不完全相等(在一种情况下,只是一个布尔值。另一种情况,是一双袜子),但是渐进复杂性确实相等的。
【原文链接:Stack Overflow】












- 评论最多
- 最新评论
- 随机文章
- 气象报文的释读
- 毫无PS痕迹的计算机生成图片
- 巴洛特利
- 如何挖矿:Bitcoin教程
- 世界十大黑客
- 被诅咒的程序员的七宗罪
- 硬件强悍,算法是否已经不再重要?
- 二十四节气计算公式
- 短信猫指令at全集一览表方便查询
- 为什么没有那么多女程序员
趣头条 在 《GIT 如何删除某个本地的提交》
鸟儿叫,花儿笑,一年一季春来到!屌炸天 在 《GIT 如何删除某个本地的提交》
新春佳节到。祝好!祝好!
不错!不错!感觉好极了!1163848899 在 《GIT 如何删除某个本地的提交》
博客还真是个好东西!民间秘术 在 《军残证规则》
转眼又是新一年,博主万事如意不差钱!致富技术 在 《军残证规则》
初来乍到,无条件支持!套图 在 《军残证规则》
深受启发,无条件支持!套图网 在 《军残证规则》
毫无疑问,这个是要支持的!百万套图一键转存 在 《ASP.NET C#各种数据库连接字符串大全》
丁酉年(鸡)九月初十 2017-10-29到此一游!健康网 在 《ASP.NET C#各种数据库连接字符串大全》
学海无涯,博客有道!拜读咯!
